We construct a geographically diverse dataset GeoDE that is approximately balanced across 6 world regions. We visualize the images per region, and compare our distribution (right) to that of a previously created diverse dataset GeoYFCC (left).
Paper
Code
Download dataset
Abstract
Current dataset collection methods typically scrape large amounts of data from the web. While this technique is extremely scalable, data collected in this way tends to reinforce stereotypical biases, can contain personally identifiable information, and typically originates from Europe and Northern America. In this work, we rethink the dataset collection paradigm and introduce GeoDE, a geographically diverse dataset containing 61,940 images from 40 classes and 6 world regions and contains no personally identifiable information, collected through crowd-sourcing. We analyse GeoDE to understand differences in images collected in this manner compared to web-scraping. Despite the smaller size of this dataset, we demonstrate its use as both an evaluation and training dataset, highlight shortcomings in current models, as well as show improved performances when even small amounts of GeoDE (1000 - 2000 images per region) are added to a training dataset. GeoDE is released under a CC BY license.
Citation
@inproceedings{ramaswamy2022geode,
author = {Vikram V. Ramaswamy and Sing Yu Lin and Dora Zhao and Aaron B. Adcock and Laurens van der Maaten and Deepti Ghadiyaram and
Olga Russakovsky},
title = {GeoDE: a Geographically Diverse Evaluation Dataset for Object Recognition},
booktitle = {NeurIPS Datasets and Benchmarks},
year = {2023}
}
Crowdsourcing a geodiverse dataset
We ask participants from 6 different regions of the world to send us images of 40 different objects. This results ins a dataset comprising of 61,940 images roughly balanced across both these objects and regions. More details about the crowd-sourcing itself, along with specific objects and regions chosen are here.
Comparison to ImageNet
Shown are sample images of two object classes in different regions within GeoDE (and ImageNet in the bottom row, for comparison). Product labels on images have been blurred.
We compare GeoDE to 2 other datasets collected to be geographically diverse: GeoYFCC and DollarStreet. We see that GeoDE is more geographically diverse than GeoYFCC, and is much larger than DollarStreet.
Dataset
Size; distribution
Collection process; annotation process
Geographic coverage
Personally Identifiable Info (PII)
GeoDE
61,940 images; balanced across 40 classes and 6 regions
Crowd-sourced collection using paid workers; manual annotation
Even distribution over six geographical regions (West Asia, Africa, East Asia, Southeast Asia, Americas and Europe)
Images by professional and volunteer photographers; manual labels including household income
63 countries in four regions (Africa, America, Asia and Europe); not balanced
Yes, with permission
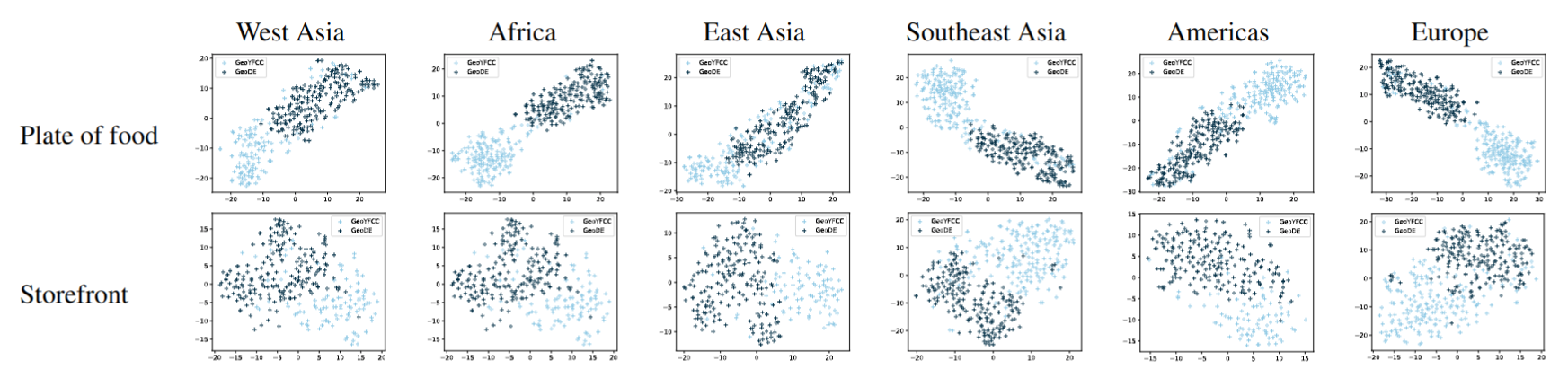
We attempt to quantify the difference in object appearance of images from GeoYFCC and GeoDE. Using features extracted from a ResNet50 model trained on the PASS dataset, we visualize these datasets using TSNE. Despite conditioning on both the region and object, we see that images from these two datasets have very different features.
Evaluating current models
We evaluate performance of models trained on other datasets on GeoDE to identify issues within these models. We show that there is a disparity in performance of these models based on region: below, we show the performance of CLIP and an ImageNet trained model on GeoDE. Region with the best performance is bolded, region with the worst performance is underlined.
Model
Africa
East Asia
Southeast Asia
Americas
West Asia
Europe
ImageNet
62.7
63.3
67.3
68.6
69.4
69.9
CLIP
78.7
79.9
81.9
84.4
84.0
85.8
We also visualize misclassified images from the classes that have the least accuracy for the CLIP model, along with the predicted label. We see that there are some objects that the model struggles to identify (like "medicine", which gets predicted as "hand soap" or "toothpaste/toothpowder" ) as well as some classes that contain stereotypes ("house" is often predicted to be "religious building").
Related Work
Below are some papers related to our work. We discuss them in more detail in the related work section of our paper.
This material is based upon work partially supported by the National Science Foundation under Grant No. 2145198. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation. We also acknowledge support from Meta AI and the Princeton SEAS Howard B. Wentz, Jr. Junior Faculty Award to OR.
We thank Dhruv Mahajan for his valuable insights during the project development phase. We also thank Jihoon Chung, Nicole Meister, Angelina Wang and the Princeton Visual AI Lab for their helpful comments and feedback during the writing process.